Annons
Vi kan prata med nästan alla våra prylar nu, men exakt hur fungerar det? När du frågar "Vilken låt är det här?" eller säga "Ring mamma", ett mirakel av modern teknik händer. Och även om det känns som om det är i framkant går denna idé om att prata med enheter årtionden tillbaka - nästan så långt som jetpacks inom science fiction!
Idag är huvuddelen av uppmärksamheten på röststyrd dator på smartphones. Apple, Amazon, Microsoft och Google är i toppen av kedjan, var och en erbjuder sitt eget sätt att prata med elektronik. Du visste vem de är: Siri, Alexa, Cortana och den namnlösa ”Ok, Google” som. Vilket väcker en stor fråga ...
Hur tar en enhet talade ord och förvandlar dem till kommandon den kan förstå? I huvudsak handlar det om mönstermatchning och göra förutsägelser baserade på dessa mönster. Mer specifikt är röstigenkänning en komplex uppgift som kommer från Akustisk modellering och Språkmodellering.
Akustisk modellering: vågformer och telefoner
Akustisk modellering är processen att ta en vågform av tal och analysera den med hjälp av statistiska modeller. Den vanligaste metoden för detta är
Dold Markov-modellering, som används i vad som kallas uttal modellering att dela upp talet i komponentdelar som kallas telefoner (inte förväxlas med faktiska telefonenheter). Microsoft har varit en ledande forskare på detta område i många år.Dold Markov-modellering: sannolikhetsstater
Dold Markov-modellering är en prediktiv matematisk modell där det aktuella tillståndet bestäms genom att analysera utgången. Wikipedia har en bra exempel med två vänner.
Föreställ dig två vänner - Local Friend och Remote Friend - som bor i olika städer. Local Friend vill ta reda på hur vädret är där Remote Friend bor, men Remote Friend vill bara prata om vad han gjorde den dagen: gå, shoppa eller städa. Sannolikheten för varje aktivitet beroende på dagens väder.
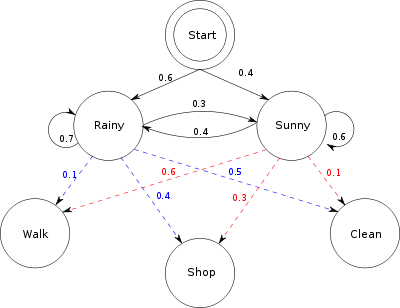
Låtsas att detta är den enda tillgängliga informationen. Med den kan Local Friend hitta trender i hur vädret förändrats från dag till dag, och att använda dessa trender, hon kan börja göra utbildade gissningar om vad dagens väder kommer att baseras på hennes väns aktivitet igår. (Du kan se ett diagram över systemet ovan.)
Om du vill ha ett mer komplext exempel, kolla in detta exempel på Matlab. Vid röstigenkänning jämför denna modell i huvudsak varje del av vågformen mot vad som kommer före och vad som kommer efter, och mot en ordlista med vågformer för att ta reda på vad som sägs.
I grund och botten, om du gör ett "ljud" kommer det att kontrollera det ljudet mot de mest troliga ljuden som vanligtvis kommer före och efter det. Kanske betyder det att kontrollera mot “e” -ljudet, “at” -ljudet och så vidare. När mönstret matchar korrekt har det hela ditt ord. Detta är en överförenkling, men du kan se Microsofts hela förklaring här.
Språkmodellering: mer än ljud
Akustisk modellering gör långt för att hjälpa din dator att förstå dig, men hur är det med homonymer och regionala variationer i uttal? Det är där språkmodellering spelar in. Google har drivit mycket forskning på detta område, främst genom användning av N-gram modellering.
När Google försöker förstå ditt tal gör det det baserat på modeller som härrör från dess massiva bank av röstsökning och YouTube-transkriptioner. Alla dessa lustiga felaktiga bildtexter har faktiskt hjälpt Google att utveckla sina ordböcker. De använde också de som lämnade GOOG-411 för att samla information om hur människor pratar.

Hela denna språksamling skapade ett stort antal uttal och dialekter, vilket skapade en robust ordbok och hur de låter. Detta möjliggör matchningar som har en kraftigt reducerad felfrekvens än matchning av brute-krafter baserat på råvaror Du kan läsa en kort uppsats som beskriver deras metoder här.
Medan Google är ledande inom detta område finns det andra matematiska modeller som utvecklas, inklusive kontinuerligt utrymme modeller och positionella språkmodeller, som är mer avancerade tekniker som kommer från forskning inom konstgjord intelligens. Dessa metoder är baserade på att replikera vilken typ av resonemang människor gör när de lyssnar på varandra. Dessa är mycket mer avancerade både vad gäller tekniken bakom dem, men också den matematik och programmering som krävs för att kartlägga dessa modeller.
N-Gram modellering: Sannolikhet möter minne
N-gram modellering fungerar baserat på sannolikheter, men det använder en befintlig ordbok med ord för att skapa ett grenat träd av möjligheter, som sedan slätas ut för effektivitetsskull. På ett sätt betyder detta att N-gram Modeling avskaffar mycket av osäkerheten i ovannämnda Hidden Markov Modeling.
Som nämnts ovan kommer denna metods styrka från att ha en stor ordlista med ord och användande, inte bara primitiva ljud. Detta ger programmet förmågan att berätta skillnaden mellan homofoner, som "beat" och "betor". Det är kontextuellt, vilket betyder att när du pratar om gårdagens poäng, inte programmet drar upp ord om borscht.
Men dessa modeller är faktiskt inte de bästa för språket, främst på grund av problem med ordsannolikhet i längre fraser. När du lägger till fler ord i en mening blir den här modellen lite av eftersom dina tidiga ord troligen inte har laddat allt som behövs för din fullständiga tanke.
Men det är enkelt och enkelt att implementera, vilket gör det till en bra match för ett företag som Google som gillar att kasta servrar på beräkningsproblem. Du kan läsa mer om N-gram Modelieng på University of Washington, eller så kan du titta på en föreläsning på Coursera.
Shouting at Clouds: Apps & Devices
Alla som har använt Siri känner frustrationen över en långsam nätverksanslutning. Det beror på att dina kommandon till Siri skickas över nätverket för att avkodas av Apple. Cortana för Windows-telefon kräver också en nätverksanslutning för att fungera korrekt. Däremot är Amazons Echo bara en Bluetooth-högtalare utan internet.
Varför skillnaden? Eftersom Siri och Cortana behöver tunga servrar för att avkoda ditt tal. Kan det göras på din telefon eller surfplatta? Visst, men du skulle döda din prestanda och batteritid under processen. Det är bara mer meningsfullt att ladda ner behandlingen till dedikerade maskiner.
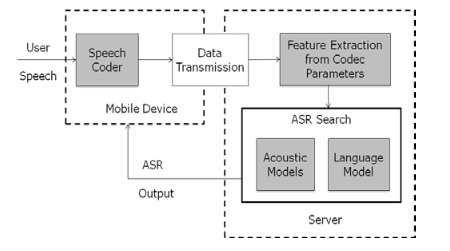
Tänk på det så här: ditt kommando är en bil som sitter fast i leran. Du kan förmodligen skjuta ut det själv med tillräckligt med tid och ansträngning, men det kommer att ta timmar och lämna dig utmattad. Istället ringer du vägassistans och de drar ut din bil på bara några minuter. Nackdelen är att du måste ringa och vänta på dem, men det är fortfarande snabbare och mindre beskattande.
Skrivbordsmodeller som Nuance brukar använda lokala resurser på grund av den kraftigare hårdvaran. När allt kommer omkring, säger Steve Jobs, din skrivbordet är en lastbil. (Vilket gör det lite dumt att OS X använder servrar för dess behandling.) Så när du behöver bearbeta språk och röst är det redan utrustat tillräckligt bra för att hantera det på egen hand.
Å andra sidan tillåter Android utvecklare att inkludera offline taligenkänning i sina appar. Google gillar att gå före tekniken, och du kan satsa på att de andra plattformarna kommer att få denna förmåga när deras hårdvara blir kraftigare. Ingen gillar det när dålig täckning eller dålig mottagning lobotomiserar sin enhet.
Börja använda röstkommandon nu
Nu när du känner till de grundläggande koncepten bör du leka med dina olika enheter. Testa det nya röstskrivning i Google Dokument Hur röstskrivning är den nya bästa funktionen i Google DokumentRöstigenkänning har förbättrats med höga språng under de senaste åren. Tidigare denna vecka introducerade Google äntligen röstskrivning i Google Docs. Men är det bra? Låt oss ta reda på! Läs mer . Som om webbkontorssviten inte redan var tillräckligt kraftfull låter röststyrning dig diktera och formatera dina dokument helt. Detta utvidgas med den kraftfulla teknik som de redan har designat för Chrome och Android.
Andra idéer inkluderar att ställa in din Mac för att använda röstkommandon Hur man använder talkommandon på din Mac Läs mer och ställa in din Amazon Echo med automatiserad kassa Hur Amazon Echo kan göra ditt hem till ett smart hemSmart home tech är fortfarande i sina tidiga dagar, men en ny produkt från Amazon som heter "Echo" kan hjälpa till att få den in i mainstream. Läs mer . Lev i framtiden och omfamna prata med dina prylar - även om du bara beställer fler pappershanddukar. Om du är smarttelefonberoende har vi också handledning för Siri 8 saker du förmodligen inte insett att Siri kunde göraSiri har blivit en av iPhone: s definierande funktioner, men för många är det inte alltid det mest användbara. En del av detta beror på begränsningarna av röstigenkänning, men konstigheten med att använda ... Läs mer , Cortana 6 coolaste saker du kan kontrollera med Cortana i Windows 10Cortana kan hjälpa dig att gå handsfree i Windows 10. Du kan låta henne söka i dina filer och på webben, göra beräkningar eller dra upp väderprognosen. Här täcker vi några av hennes coolare färdigheter. Läs mer , och Android OK, Google: 20 användbara saker du kan säga till din Android-telefonGoogle Assistant kan hjälpa dig att göra mycket på din telefon. Här är en hel massa grundläggande men användbara OK-kommandon för Google att prova. Läs mer .
Vad är din favoritanvändning av röststyrning? Låt oss veta i kommentarerna.
Bildkrediter: T-flex via Shutterstock, Terencehonles via Wikimedia Foundation, Arizona State, Cienpies Design via Shutterstock
Michael använde inte en Mac när de var dömda, men han kan koda i Applescript. Han har examen i datavetenskap och engelska; han har skrivit om Mac, iOS och videospel ett tag nu; och han har varit IT-apa på dagtid i över ett decennium, specialiserat på skript och virtualisering.

