Annons
Är du en troende på idén att när något publiceras på Internet så publiceras det för alltid? Tja, idag kommer vi att fördriva den myten.
Sanningen är att det i många fall är fullt möjligt att utrota information från Internet. Visst, det finns en post med webbsidor som har tagits bort om du söker på Wayback-maskin, höger? Japp, absolut. På Wayback Machine finns det register över webbsidor som går tillbaka många år - sidor som du inte hittar med en Google-sökning eftersom webbsidan inte längre finns. Någon raderade det, annars höll webbplatsen avstängd.
Så det finns inget att komma runt det, eller hur? Information kommer för evigt att graveras in i stenen på Internet, där i generationer att se? Tja, inte exakt.
Sanningen är att även om det kan vara svårt eller omöjligt att utplåna stora nyheter som har spridit sig från en ny webbplats eller blogg till en annan som ett virus, det är faktiskt ganska enkelt att helt radera en webbsida eller flera webbsidor från alla existerande poster - att ta bort den sidan för såväl sökmotorer som de
Wayback-maskin Den nya Wayback-maskinen låter dig visuellt resa tillbaka i Internet-tidDet verkar som om Wayback Machine-lanseringen 2001, webbplatsägarna har beslutat att kasta ut den Alexa-baserade back-enden och göra om den med sin egen open source-kod. Efter att ha genomfört test med ... Läs mer . Det finns naturligtvis en fångst, men vi kommer till det.3 sätt att ta bort bloggsidor från nätet
Den första metoden är den som majoriteten av webbplatsägare använder, eftersom de inte vet något bättre - helt enkelt ta bort webbsidor. Det kan hända för att du har insett att du har duplicerat innehåll på din webbplats eller för att du har en sida som du inte vill visa upp i sökresultaten.
Ta bara bort sidan
Problemet med att helt radera sidor från din webbplats är att eftersom du redan har skapat sidan på netto, det finns sannolikt länkar från din egen webbplats såväl som externa länkar från andra webbplatser till just den sida. När du tar bort den känner Google genast den sidan som din saknas som en saknad sida.
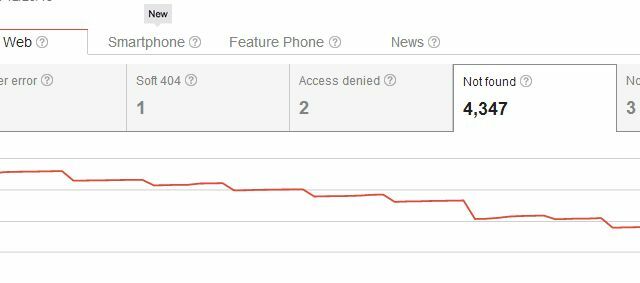
Så när du tar bort din sida har du inte bara skapat ett problem med "Inte hittat" genomsökningsfel för dig själv, utan du har också skapat ett problem för alla som någonsin länkar till sidan. Vanligtvis ser användare som kommer till din webbplats från en av dessa externa länkar din 404-sida, som inte är en stora problem, om du använder något som Googles anpassade 404-kod för att ge användarna användbara förslag eller alternativ. Men du kan tro att det kan finnas mer graciösa sätt att ta bort sidor från sökresultaten utan att starta av alla de 404: erna för befintliga inkommande länkar, eller hur?
Det finns det.
Ta bort en sida från Googles sökresultat
Först och främst bör du förstå att om webbsidan du vill ta bort från Googles sökresultat inte är en sida från din egen webbplats, då har du lycka till om det inte finns lagliga skäl eller om webbplatsen har publicerat din personliga information online utan din tillstånd. Om det är så kan du använda Googles felsökare för borttagning att skicka en begäran om att ta bort sidan från sökresultaten. Om du har ett giltigt ärende, kan det hända att du får framgång med att sidan har tagits bort - naturligtvis kan du ha ännu större framgång bara kontakta webbplatsägaren Hur man tar bort falsk personlig information på InternetOnline-sekretess garanteras inte längre. Lär dig hur du rapporterar en webbplats och tar bort personlig information från internet. Läs mer som jag beskrev hur man gör tillbaka 2009.
Om sidan du vill ta bort från sökresultaten finns på din egen webbplats har du tur. Allt du behöver göra är att skapa en robots.txt arkivera och se till att du inte har tillåtit antingen den specifika sida som du inte vill ha i sökresultaten eller hela katalogen med innehållet som du inte vill indexeras. Så här ser blockering av en enda sida ut.
Användaragent: * Disallow: /my-deleted-article-that-i-want-removed.html
Du kan blockera bots från att genomsöka hela kataloger på din webbplats på följande sätt.
Användaragent: * Disallow: / content-about-personal-stuff /
Google har en utmärkt support sida som kan hjälpa dig att skapa en robots.txt-fil om du aldrig har skapat en tidigare. Detta fungerar mycket bra, som jag nyligen förklarade i en artikel om strukturering av syndikationsavtal Hur man förhandlar om syndikationsavtal och skyddar dina sökrankningarSyndicating är all raseri i dag. Men plötsligt kunde du upptäcka att syndikationspartnern listas högre än du i sökresultaten efter en berättelse som du ursprungligen skrev! Skydda dina sökrankningar. Läs mer så att de inte skadar dig (ber syndikationspartner om att inte tillåta indexering av deras sidor där du syndikeras). När min egen syndikationspartner gick med på att göra detta försvann sidorna som duplicerade innehåll från min blogg helt från söklistorna.
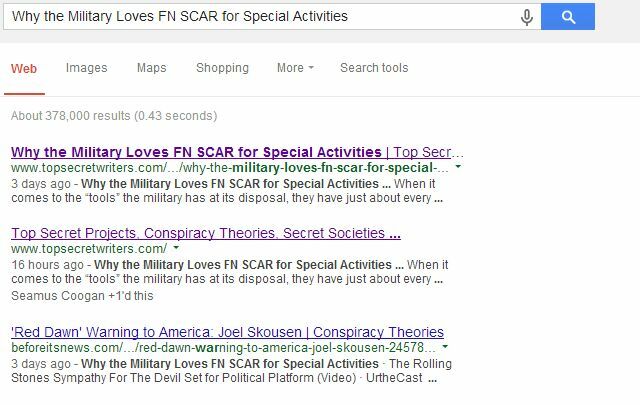
Endast huvudwebbplatsen kommer upp på tredje plats för sidan där de listar vår titel, men min blogg är nu listad på både första och andra platsen; något som skulle ha varit nästan omöjligt om en webbplats med högre myndigheter lämnat den duplicerade sidan indexerad.
Vad många inte inser är att det också är möjligt att åstadkomma med Internet Archive (Wayback Machine). Här är de rader du behöver lägga till din robots.txt-fil för att få det att hända.
Användaragent: ia_archiver. Disallow: / sample-category /
I det här exemplet ber jag Internetarkivet att ta bort allt i underkatalogen för provkategori på min webbplats från Wayback Machine. Internetarkivet förklarar hur man gör detta på deras hjälpsida för uteslutning. Här förklarar de också att "Internetarkivet inte är intresserat av att erbjuda åtkomst till webbplatser eller andra internetdokument vars författare inte vill ha sina material i samlingen."
Detta flyger i strid med den vanliga uppfattningen att allt som publiceras på Internet får sopas upp i arkivet för all evighet. Nope - webbansvariga som äger innehållet kan specifikt ta bort innehållet från arkivet med hjälp av robots.txt-metoden.
Ta bort en enskild sida med metataggar
Om du bara har några få enskilda sidor som du vill ta bort från Googles sökresultat behöver du faktiskt inte använda robots.txt-metoden överhuvudtaget kan du helt enkelt lägga till rätt "robot" -metatagg på de enskilda sidorna och säga robotarna att inte indexera eller följa länkar på hela sida.
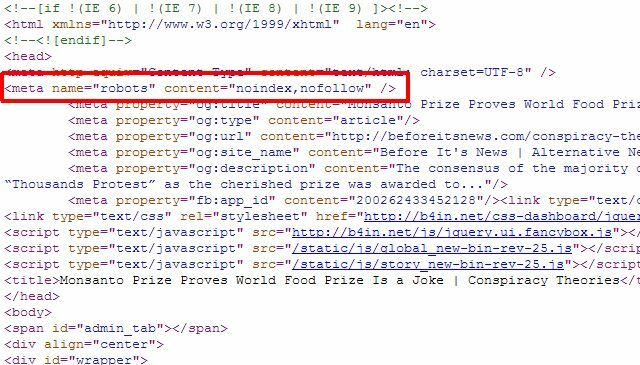
Du kan använda metoden "robotar" ovan för att hindra robotar från att indexera sidan, eller så kan du specifikt berätta för Google-roboten att inte indexera så att sidan bara tas bort från Googles sökresultat, och andra sökrobotar kan fortfarande komma åt sidan innehåll.
Det är helt upp till dig hur du vill hantera vad robotar gör med sidan och huruvida sidan listas eller inte. För bara några enskilda sidor kan detta vara den bättre metoden. Gå till metoden robots.txt om du vill ta bort en hel katalog med innehåll.
Idén att ”ta bort” innehåll
Denna typ vänder hela tanken på att "ta bort innehåll från Internet" på huvudet. Tekniskt sett om du tar bort alla dina egna länkar till en sida på din webbplats och tar bort dem från Google Search och Internetarkiv med hjälp av robots.txt-tekniken, sidan är för alla syften och "syftar" från Internet. Det coola är dock att om det finns befintliga länkar till sidan fungerar dessa länkar fortfarande och du kommer inte att utlösa 404-fel för de besökarna.
Det är en mer "skonsam" strategi för att ta bort innehåll från Internet utan att helt krossa din webbplats befintliga länk popularitet över Internet. I slutändan, hur du gör för att hantera vilket innehåll som samlas in av sökmotorer och Internetarkivet är upp till dig, men alltid kom ihåg att trots vad folk säger om livslängden för saker som läggs ut på nätet, är det verkligen helt inom ditt kontrollera.
Ryan har en kandidatexamen i elektroteknik. Han har arbetat 13 år inom automationsteknik, 5 år inom IT och är nu en applikationsingenjör. Han var tidigare chefredaktör för MakeUseOf och talade vid nationella konferenser om datavisualisering och har varit med på nationell TV och radio.